We can conclude that, if there is not an exceptional talent behind the enormous success of some people, another factor is probably at work. Our simulation clearly shows that such a factor is just pure luck. — Pluchino, Biondo, Rapisarda
We argue this conclusion is baked into the structure of the model from the start.
In the TvL model a person in the 95th percentile of talent has roughly a 6.1% chance of doubling their capital each timestep; a person in the 5th percentile has 3.4%. The difference between extreme outliers is only ~2.6 percentage points per timestep. Starting from such a small difference between talent levels essentially guarantees the conclusion before the simulation even runs.
What makes the model’s outcome inevitable is its multiplicative structure. While the average capital grows slightly for talented people, the geometric-mean growth rate — which governs typical long-run paths — is negative for everyone with talent below 1. A few lucky individuals capture enormous gains, pulling the arithmetic mean up, while for realistic talent levels in this model, most people lose capital. This asymmetry is baked into the model by construction: talent can help you capitalize on lucky events, but it offers zero protection against unlucky ones.
The TvL Model
A high-level description of the model from the paper:
\(N\) people are placed uniformly at random in a square environment and stay fixed.
\(N\) events are also placed uniformly at random, each classified as Lucky or Unlucky (50/50).
The events randomly walk the environment each timestep.
At each timestep, capital is updated:
No overlap with an event: capital unchanged.
Overlap with an Unlucky event: capital halved.
Overlap with a Lucky event: if a uniform random draw \(u \in [0,1)\) is less than the person’s talent score, capital doubles; otherwise unchanged.
Talent is drawn from \(\mathcal{N}(0.6,\ 0.1^2)\), truncated to \([0,1]\). Everyone starts with 10 units of capital and the simulation runs for 80 timesteps.
The one parameter the paper does not give explicitly is \(p_\text{event}\) — the probability that a given person overlaps an event at a given timestep. We estimate it in the appendix; our best estimate is 0.16.
Setup
Imports and parameters
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as ssrng = np.random.default_rng(seed=20180312)# Paper's parametersN_PEOPLE =1000N_TIMESTEPS =80STARTING_CAPITAL =10.0TALENT_MEAN =0.6TALENT_SD =0.1P_LUCKY =0.5# Our estimate of p_event (derived in appendix)P_EVENT =0.16
The difference in the probability of doubling between the 95th and 5th percentile is only ~2.6 percentage points. The probability of halving is identical for everyone — talent offers no protection from bad luck at all.
Figure 1: Per-timestep outcome probabilities across all talent quantiles. The 5th and 95th percentiles are marked. The tiny difference in the blue ‘doubles’ band is the entire effect of talent in this model.
Mean vs Geometric Mean: The Multiplicative Trap
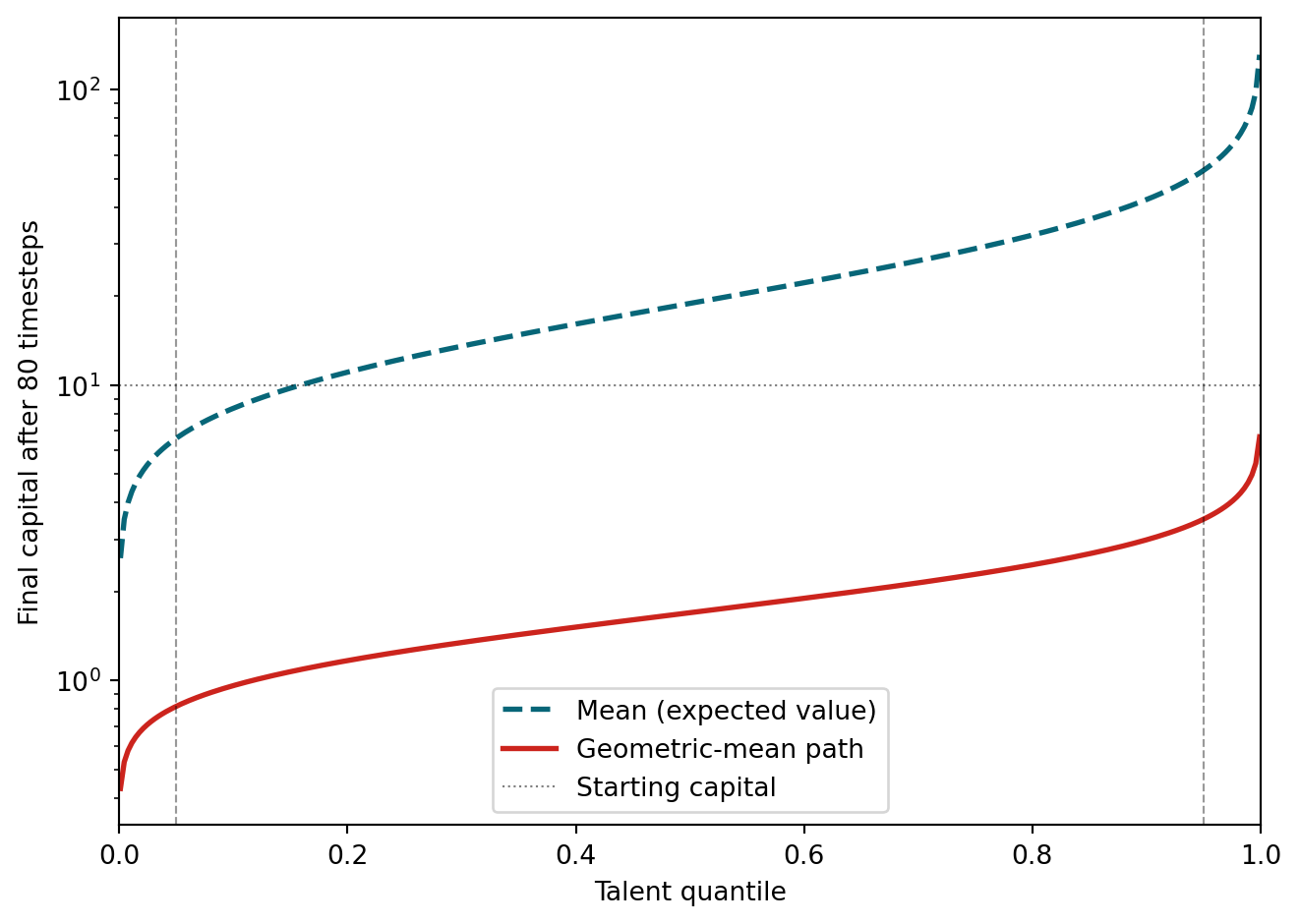
Because we have analytical probabilities, we can compute both the expected (mean) final capital and the geometric-mean growth rate for any talent quantile. No simulation needed.
The expected value of each timestep multiplier is \(E[m] = 2 p_\text{double} + 1 \cdot p_\text{same} + 0.5 \cdot p_\text{halve}\), which is above 1 for talent > 0.5. But capital is a multiplicative process — the long-run growth rate is governed by the geometric mean of the per-step multiplier: \(\exp(p_\text{double} \ln 2 + p_\text{halve} \ln 0.5)\). This geometric mean is below 1 for all talent < 1, meaning capital shrinks on a typical path even though the arithmetic mean grows.
The mean and the geometric-mean path tell completely different stories. The mean grows — a 95th-percentile person has an expected final capital over 50. But the geometric-mean path shrinks for every talent level below perfect: a 95th-percentile person’s typical-path capital is about 3.5, down from 10. Only someone with literally perfect talent (\(T = 1\)) has a non-shrinking geometric mean.
This is the signature of a multiplicative process. A few people get lucky runs — several doublings without any halvings — and their enormous gains pull the arithmetic mean far above what most people actually experience. The mean is dominated by rare winners; the geometric mean reflects typical long-run growth.
A caveat: over a finite horizon like 80 steps, variance is high enough that extremely talented individuals still have a meaningful chance of coming out ahead. The geometric mean governs the long-run typical path, but at 80 steps we’re not yet in the long run — the distribution of outcomes is wide, and luck can easily overcome the downward drift for any individual. This doesn’t rescue the model’s claim, though: it just means that which talented people succeed is still driven by luck.
Code
quantiles = np.linspace(0.001, 0.999, 300)fig, ax = plt.subplots(figsize=(7, 5))evs = [expected_value(q) for q in quantiles]gms = [geometric_mean_value(q) for q in quantiles]ax.plot(quantiles, evs, ls="--", lw=2, color="#076678", label="Mean (expected value)")ax.plot(quantiles, gms, ls="-", lw=2, color="#cc241d", label="Geometric-mean path")ax.axhline(STARTING_CAPITAL, color="black", lw=0.8, ls=":", alpha=0.5, label="Starting capital")for q in (0.05, 0.95): ax.axvline(q, color="black", lw=0.8, ls="--", alpha=0.4)ax.set_xlim(0, 1)ax.set_xlabel("Talent quantile")ax.set_ylabel("Final capital after 80 timesteps")ax.set_yscale("log")ax.legend()plt.tight_layout()plt.show()
Figure 2: Mean (dashed) vs geometric-mean path (solid) after 80 timesteps. The arithmetic mean grows with talent, but the geometric-mean path — reflecting typical long-run growth — stays well below starting capital for all realistic talent levels. Only perfect talent (T = 1) breaks even.
Concluding Thoughts
The TvL paper’s conclusion — that luck dominates talent — is essentially a restatement of its inputs. Two design choices do most of the work:
Tiny talent bandwidth. The difference in doubling probability between the 5th and 95th percentile of talent is only ~2.6 percentage points. With such narrow dynamic range, talent can barely move the needle.
Asymmetric multipliers. Unlucky events halve your capital regardless of talent, but lucky events only help if you’re talented enough to capitalize. In a multiplicative process, this asymmetry means the typical person loses capital over time even though the average grows — the gains are concentrated in a lucky few.
These are modeling choices, not discoveries about the world. The simulation doesn’t demonstrate that luck dominates talent — it assumes a structure where that outcome is nearly inevitable. This is not to say luck is unimportant in real life; it may well dominate. But this particular model can’t tell us that.
Ergodicity Economics by Ole Peters — the formal mathematical framework for why geometric means diverge from arithmetic means in multiplicative processes.
The Kelly Criterion — the classic solution for maximizing geometric growth under uncertainty.
The Success Equation by Michael Mauboussin — on how luck becomes dominant when skill levels converge (“the Paradox of Skill”).
Naval Ravikant on the four kinds of luck — challenges the assumption that luck is purely external by explaining how talent and agency can increase the frequency of lucky events.
Appendix: Estimating p_event
The paper does not state \(p_\text{event}\) directly. We infer it by finding values that reproduce the maximum number of unlucky events seen in the paper’s Figure 5b (approximately 15 events across 1,000 people). The plot below sweeps p_event over 50 simulation trials; our best estimate of 0.16 sits in the center of the plausible range.
Figure 3: Maximum unlucky events per person across 50 simulation trials, for different values of p_event. The paper’s Figure 5b shows a maximum of ~15 unlucky events; our estimate of p_event=0.16 sits in the middle of the plausible range.